Kappa
“Great things are not done by impulse, but by a series of small things brought together.”
Hack The Box
Recurrent Neural Networks
Recurrent Neural Networks (RNNs) are a class of artificial neural networks specifically designed to handle sequential data, where the order of the data points matters. Unlike traditional feedforward neural networks, which process data in a single pass, RNNs have a unique structure that allows them to maintain a "memory" of past inputs. This memory enables them to capture temporal dependencies and patterns within sequences, making them well-suited for tasks like natural language processing, speech recognition, and time series analysis.
Handling Sequential Data
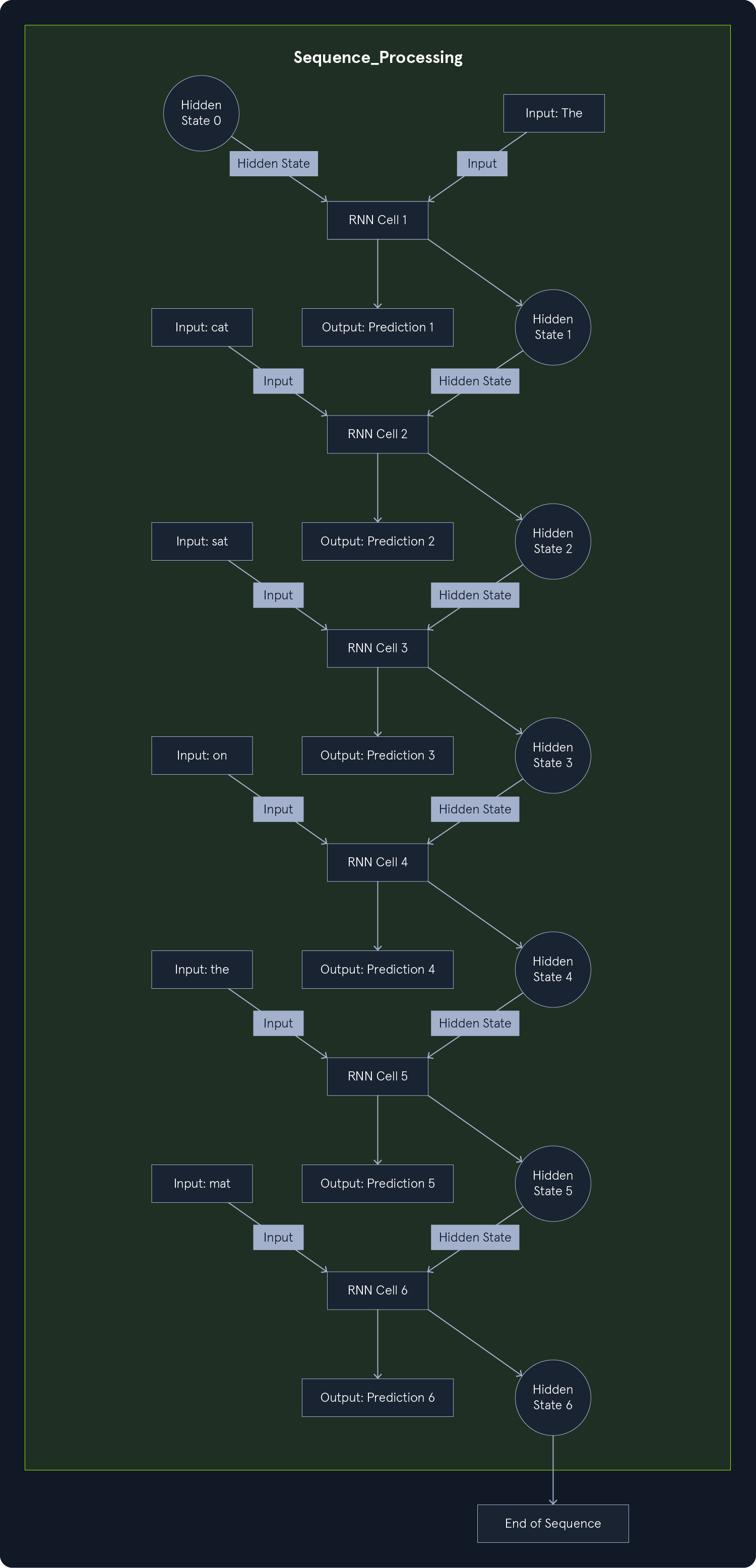
The key to understanding how RNNs handle sequential data lies in their recurrent connections. These connections create loops within the network, allowing information to persist and be passed from one step to the next. Imagine an RNN processing a sentence word by word. As it encounters each word, it considers the current input and incorporates information from the previous words, effectively "remembering" the context.
{kind=link}
This process can be visualized as a chain of repeating modules, each representing a time step in the sequence. At each step, the module takes two inputs:
- The current input in the sequence (e.g., a word in a sentence)
- The hidden state from the previous time step encapsulates the information learned from past inputs.
The module then performs calculations and produces two outputs:
- Output for the current time step (e.g., a prediction of the next word)
- An updated hidden state is passed to the next time step in the sequence.
This cyclical flow of information allows the RNN to learn patterns and dependencies across the entire sequence, enabling it to understand context and make informed predictions.
For example, consider the sentence, "The cat sat on the mat." An RNN processing this sentence would:
- Start with an initial hidden state (usually set to 0).
- Process the word "The," and update its hidden state based on this input.
- Process the word "cat," considering both the word itself and the hidden state now containing information about "The."
- Continue processing each word this way, accumulating context in the hidden state at each step.
By the time the RNN reaches the word "mat," its hidden state would contain information about the entire preceding sentence, allowing it to make a more accurate prediction about what might come next.
The Vanishing Gradient Problem
While RNNs excel at processing sequential data, they can suffer from a significant challenge known as the vanishing gradient problem. This problem arises during training, specifically when using backpropagation through time (BPTT) to update the network's weights.
In BPTT, the gradients of the loss function are calculated and propagated back through the network to adjust the weights and improve the model's performance. However, as the gradients travel back through the recurrent connections, they can become increasingly smaller, eventually vanishing to near zero. This vanishing gradient hinders the network's ability to learn long-term dependencies, as the weights associated with earlier inputs receive minimal updates.
The vanishing gradient problem is particularly pronounced in RNNs due to the repeated multiplication of gradients across time steps. If the gradients are small (less than 1), their product diminishes exponentially as they propagate back through the network. This means that the influence of earlier inputs on the final output becomes negligible, limiting the RNN's ability to capture long-range dependencies.
LSTMs and GRUs
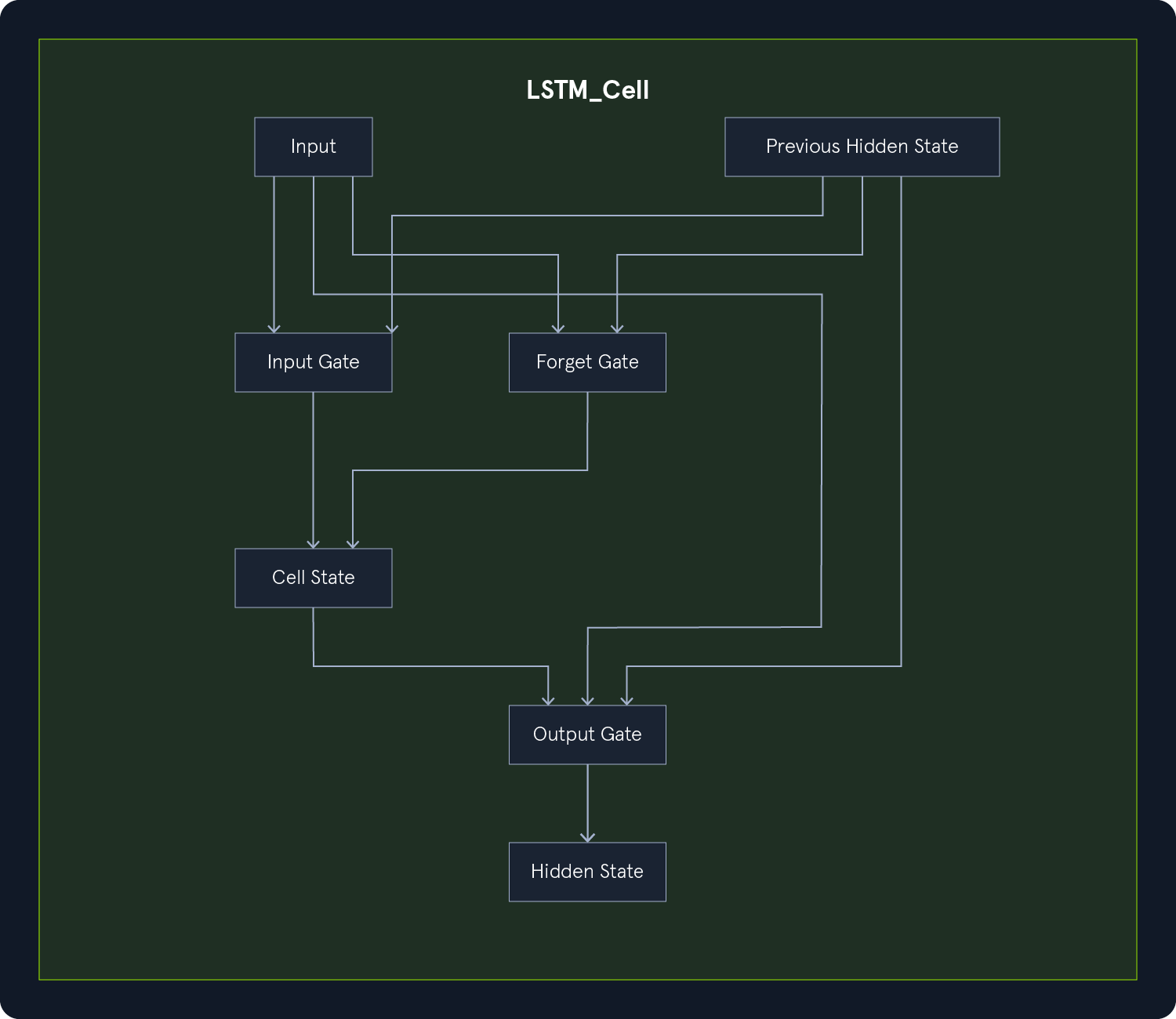
To address the vanishing gradient problem, researchers have developed specialized RNN architectures, namely Long-Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) networks. These architectures introduce gating mechanisms that control the flow of information through the network, allowing them to better capture long-term dependencies.
{kind=link}
LSTMs incorporate memory cells that can store information over extended periods. These cells are equipped with three gates:
- Input gate: - Regulates the flow of new information into the memory cell.
- Forget gate: - Controls how much of the existing information in the memory cell is retained or discarded.
- Output gate: - Determines what information from the memory cell is output to the next time step.
These gates enable LSTMs to selectively remember or forget information, mitigating the vanishing gradient problem and allowing them to learn long-term dependencies.
{kind=link}
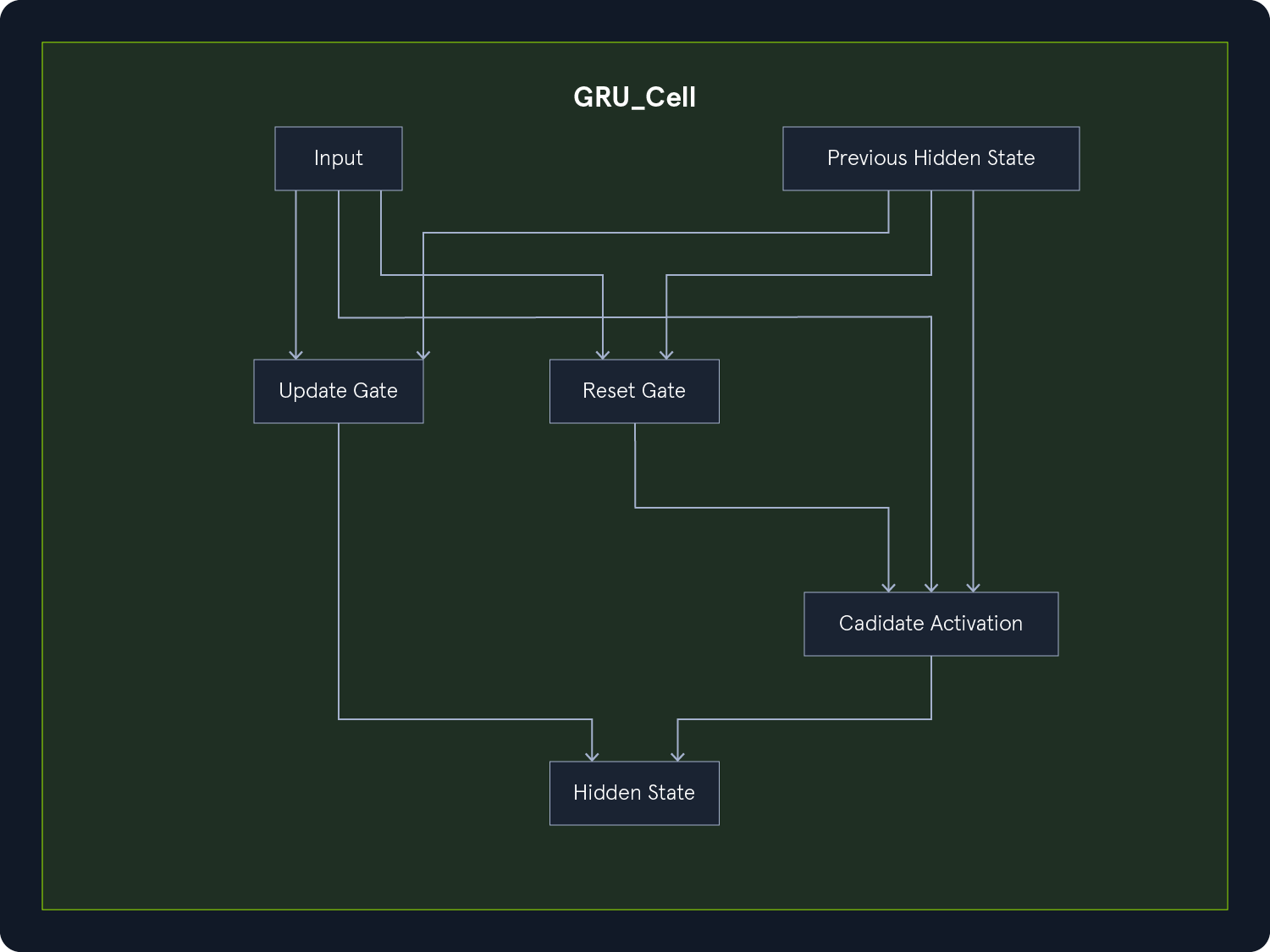
GRUs offer a simpler alternative to LSTMs, with only two gates:
- Update gate: - Controls how much of the previous hidden state is retained.
- Reset gate: - Determines how much of the previous hidden state is combined with the current input.
GRUs achieve comparable performance to LSTMs in many tasks while being computationally more efficient due to their reduced complexity.
LSTMs and GRUs have proven highly effective in overcoming the vanishing gradient problem, leading to significant advancements in sequence modeling tasks, including machine translation, speech recognition, and sentiment analysis.
Bidirectional RNNs
In addition to the standard RNNs that process sequences in a forward direction, there are also bidirectional RNNs. These networks process the sequence in both forward and backward directions simultaneously. This allows them to capture information from past and future contexts, which can be beneficial in tasks where the entire sequence is available, such as natural language processing.
A bidirectional RNN consists of two RNNs, one processing the sequence from left to right and the other from right to left. The hidden states of both RNNs are combined at each time step to produce the final output. This approach enables the network to consider the entire context surrounding each element in the sequence, leading to improved performance in many tasks.
Fundamentals of AI
- Introduction to Machine Learning
- Mathematics Refresher for AI
- Supervised Learning Algorithms
- Linear Regression
- Logistic Regression
- Decision Trees
- Naive Bayes
- Support Vector Machines (SVMs)
- Unsupervised Learning Algorithms
- K-Means Clustering
- Principal Component Analysis (PCA)
- Anomaly Detection
- Reinforcement Learning Algorithms
- Q-Learning
- SARSA (State-Action-Reward-State-Action)
- Introduction to Deep Learning
- Perceptrons
- Neural Networks
- Convolutional Neural Networks
- ~ Recurrent Neural Networks
- Introduction to Generative AI